CNDD-0251 上市公司管理层注意力时间配置词频统计——当下注意力配置
01 数据介绍
▪ 数据名称: 管理层注意力时间配置、当下注意力配置
▪ 数据编号:0251
▪ 数据范围:上市公司层面
▪ 数据年份:2010-2022
▪ 样本数量:42,335条
▪ 数据来源:根据上市公司年报管理层讨论与分析部分(MD&A)爬取
CNDeepData 数据应用质量评级
▪ 常用度:★★★★☆
▪ 稀缺度:★★★★★
▪ 新颖度:★★★★★
▪ 总体级别:14颗星
✔ 常用度:是数据市场中需求指标,是指该数据在经济管理类学术论文中使用频率。
✔ 稀缺度:是数据市场中供给指标,是指该数据在其他数据库的出现频率。
✔ 新颖度:是数据市场中生成指标,是指该数据在生成时方法新颖程度和工作量。
02 主要指标
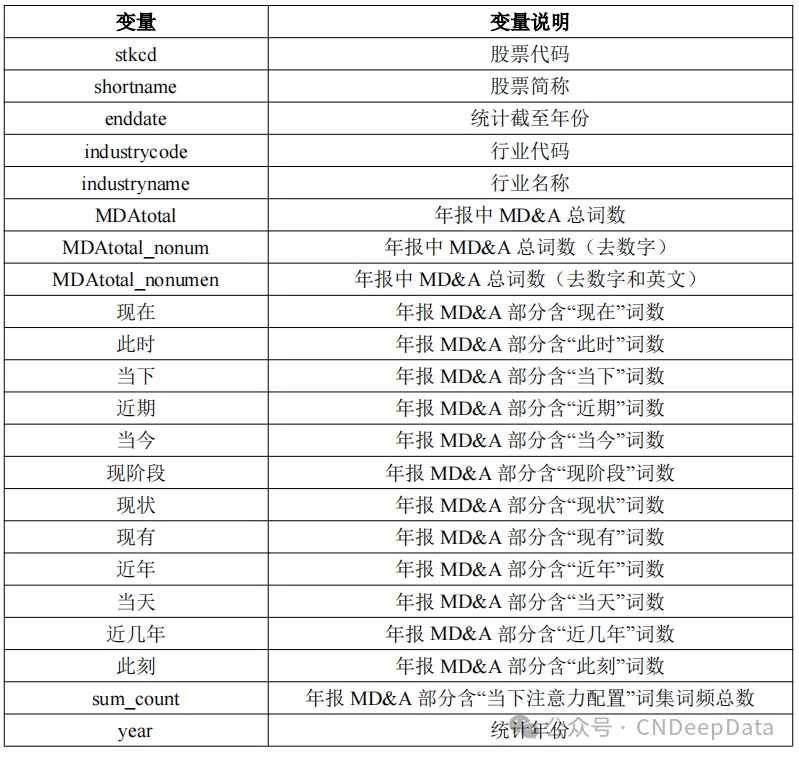
参考余振等(2024),采用对企业年报中MD&A一章进行文本分析的方法来测量企业家注意力时间配置。使用文本分析测度人们的时间配置有着较强的语言学理论基础(Chen, 2013)。跟上述做法相似,分三个步骤选取表征当下和表征未来的词集。第一步参照陈守明和胡媛媛(2016)的做法,采用“现在”“此时”“此刻”“当下”“当前”“近期”“目前”作为表征关注当下的基础词。第二步基于Word2vec中的CBOW模型构造词向量空间,并在其中寻找近义词,筛选出词频数在1000词以上,和基础词相似度在30%以上。第三步邀请3名业界和学术界专家对CBOW模型得到的相似词进行人工核查,并筛选出包括 “现在”、“此时”等表征当下的词集。
所有表征当下的词集包括:“现在”、“此时”、“当下”、“近期”、“当今”、“现阶段”、“现状”、“现有”、“近年”、“当天”、“近几年”、“此刻”。
03 数据概览
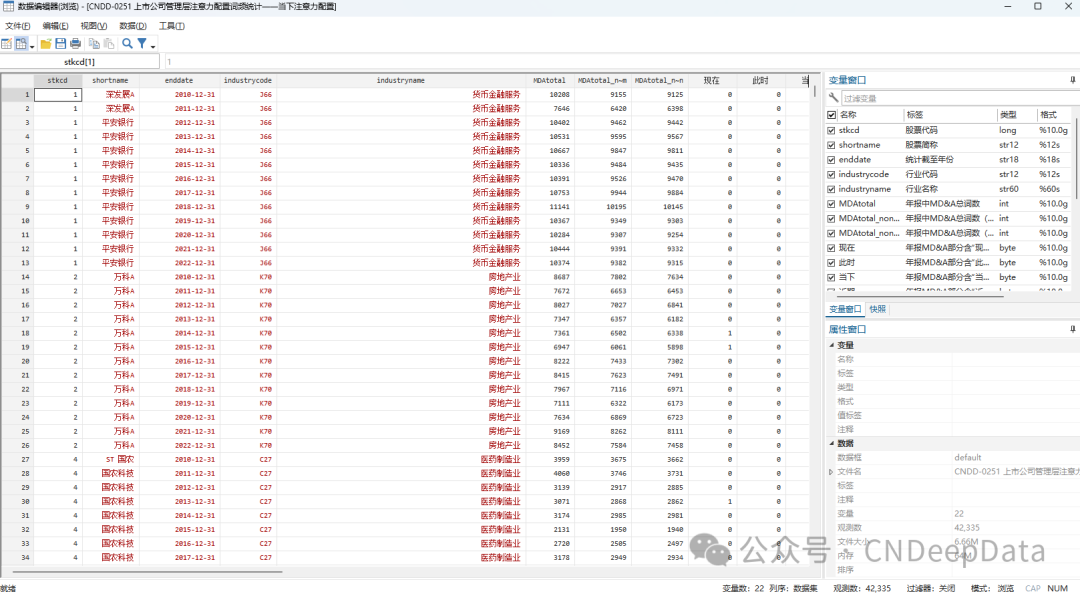
▪ 数据概览:
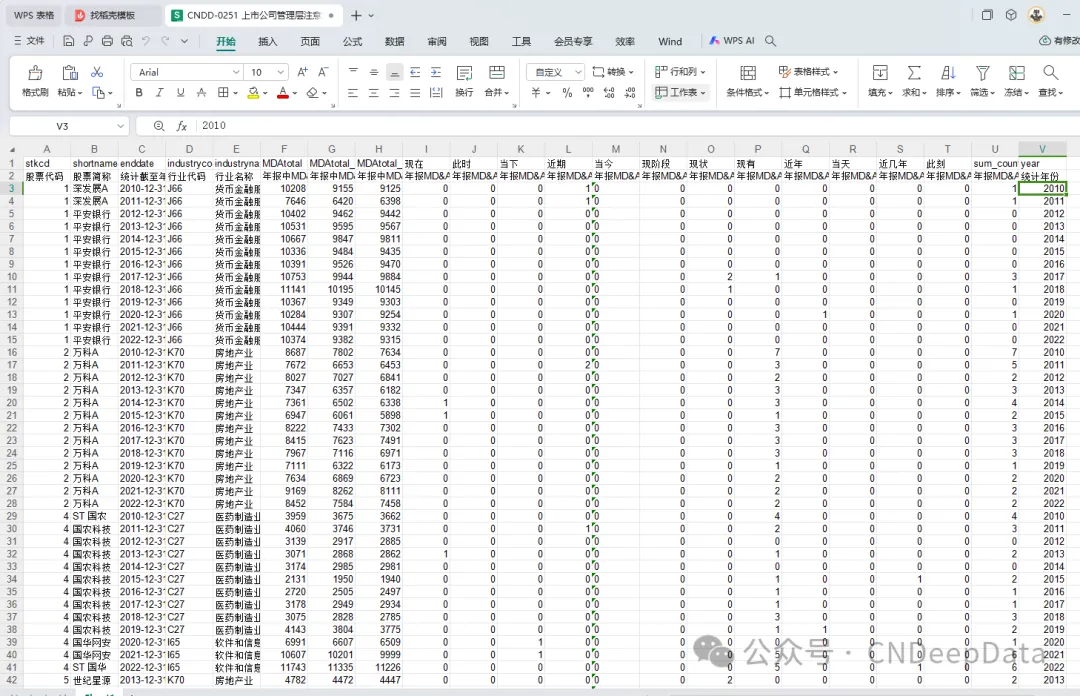
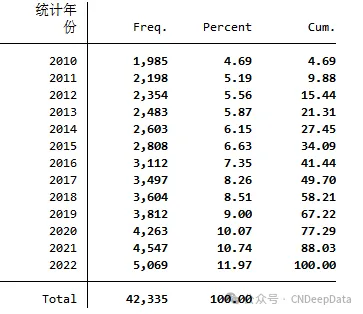
▪ 数据年度分布:
▪ 文献来源:
余振,李元琨,李汛.外部关税冲击、企业家注意力配置与创新发展[J/OL].世界经济,2024,(06):65-94[2024-10-28].
在外部环境复杂多变的背景下,研究关税变化对中国创新发展的影响机制具有重要意义。本文利用2018年美国对华加征关税这一外部冲击,使用双重差分法探究外部关税冲击对中国企业创新产出和效率的影响,并通过文本分析和 Word2vec 机器学习技术,测度了企业家注意力配置,借此进一步分析了外部负向关税冲击影响企业创新的传导机制。结果发现:外部负向关税冲击显著降低了中国企业的创新产出和创新效率;企业家注意力内容配置和注意力时间配置是产生以上影响的两个渠道;政府增加 R&D 补贴、媒体和分析师减少关注、具有抗压能力强特质的企业家,均可以缓解外部关税冲击对企业创新的负向影响。本文结论意味着要为企业家确立良好的政策导向和社会环境,缓解外部关税压力,进而使其在自主创新中更好地发挥企业家精神。
1.模型设定
为了考察外部关税冲击对企业创新的因果效应,本文以2018年美国对华加征临时性关税作为外部冲击,采用双重差分法实证研究该冲击对企业创新的影响,主要基于以下几点原因。第一,不可预测性。一般而言,临时性关税的征收首先由行业协会发起诉讼,经过调查并认定之后,再来制定相应的关税政策。这一过程往往持续数年,足以让关税被征收方的相关行业和企业做出应对(Avsar and Sevinc, 2019)。而2018年美国在调查未果的情况下就开始对华征收临时性关税,其采取措施之时机和幅度都在很多企业的预测之外。第二,规模大。2018年中美贸易摩擦被认为是在二战后全球最大规模的双边贸易摩擦(Qiu et al., 2019)。第三,科技相关。美国贸易代表办公室在第一轮关税战中发布了包含 1102 种商品的征税清单,其中包括航空航天、信息通信技术、机器人技术、工业设备、新材料和汽车等。学者们认为美国主要针对中国的高技术行业加征关税,旨在制约中国在高新技术领域的发展(余振等,2018)。因此,美国对华征收巨额关税具有一定的外生性,为识别外部关税冲击对企业创新的影响提供了政策环境。
具体而言,本文以中国受到美国加征关税冲击的企业作为处理组,以未受到美国加征关税冲击的企业为控制组,基于连续变量构造双重差分模型,识别外部关税冲击对企业创新的影响。实证模型如下所示:
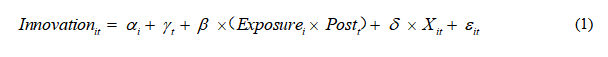
其中Exposurei为i公司的外部关税冲击指数,Postt为处理时间的虚拟变量,即在2018年及之后赋值为1,在2017年及之前赋值为0。Innovationit为企业i在t年的创新变量,包括创新产出、创新投入与创新效率三个指标。此外,本文控制了影响企业创新的其他因素,主要包括企业规模(Size)、权益收益率(ROE)、企业年龄(Age)、资本结构(Levarage)、两职合一(Dur)、董事会规模(Boardsize)。本文还控制了企业固定效应来吸收不随时间变化的企业层面的混杂因素和年份固定效应来吸收所有企业在年份层面随时间变化的混杂因素,并选择聚类到企业层面的稳健标准误,主要变量定义如附表1所示。
2.样本选择与数据来源
本文在基准回归中主要选取2015—2019年的中国上市公司作为研究对象,并在稳健性检验中,本文样本区间进一步拓展到2015—2021年的中国上市公司。选择中国上市公司作为研究样本,主要基于以下两方面的考虑:第一,数据及时可信。中国证监会对于上市公司的数据披露有严格的时间和规范要求;第二,文本公开透明。上市公司每年均会发布年报,尤其是其中的管理层分析和讨论环节经过管理层编撰和审核,其文本可以直接反映企业家的注意力配置。
本文仅选取第一轮关税冲击所针对的行业样本进行研究,原因在于以下两点。第一,针对性强。考虑到美方三轮关税壁垒针对的行业并不一样,其中第一轮贸易关税主要集中在高技术行业,而第二轮和第三轮则主要集中在农产品、工业原料和初级制成品(王孝松和武睆,2020),且更有“反制”的意味。第二,持续时间相对较长。美方对华第二轮和第三轮加征关税分别于2019年5月和9月完成,因此,美国对华征收的第一轮关税实施最早、持续时间最长,且距离后面中美第一阶段贸易协定签订的时间间隔更远。
主要数据来源于以下4个数据库,分别是美国加征关税数据库、海关数据库、上市公司专利创新数据库和上市公司年报数据库。其中美国对华加征关税数据源于美国贸易代表办公室公开的产品层面关税目录(Fajgelbaum et al., 2020)。上市公司年报数据库主要通过巨潮资讯网得到。
3.指标测度与变量定义
(1)外部关税冲击指数。本文参照Topalova and Khandelwal(2011)以及Benguria(2023)的方法计算企业层面的外部关税冲击指数。企业层面外部关税冲击指数的计算公式如下所示: 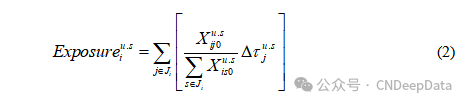
其中为中美贸易摩擦前后美方对中国j产品的关税差分值,为i公司在基期2016年对美国的j产品出口,是i公司生产的产品集合,为i公司在基期2016年对美出口总额。该指标可以看成i公司在中美贸易摩擦前后受到关税强度差分的加权平均值。具体来讲,本文首先将美国对华加征的产品层面关税在HS-6位码层面进行算术平均,与中国2016年海关库进行匹配,然后参照金祥义和戴金平(2019)的做法,匹配两个数据库中的企业名称,再将剩余样本依次按企业地址、法定代表人、邮政编码及企业电话号后 7 位进行合并。为了检验测算结果的相关特征,本文对该指标进行了描述性统计。
(2)企业创新。本文分别从企业创新投入、创新产出与创新效率多维度刻画企业创新表现。本文采用企业的研发投入金额作为创新投入指标。Hall and Harhoff(2012)、孔东民等(2017)以及黎文靖和郑曼妮(2016)的研究表明,由于专利授予受到年费、检测以及关系网络等因素的影响,专利的申请数量比授予总数更能反映公司的创新水平。而且中国的专利申请制度中将专利分为发明专利、实用新型专利和外观设计专利三种类型,其中发明专利的质量较高。因此,本文选择企业的发明专利申请量作为主要的企业创新产出指标,在稳健性检验中使用企业所有专利申请量作为替代性的创新产出指标。
基于创新产出和创新投入的密切联系,我们基于投入与产出比例构建了创新效率指标,具体本文采用企业专利申请与企业研发投入对数的比值作为企业创新效率的衡量指标(Hirshleifer et al., 2013)。这主要因为企业专利申请可以反映企业创新产出,企业研发投入金额可以反映企业创新投入。由于方程均对分母和分子取了对数,该指标可以看成企业创新产出对创新投入的弹性,即代表创新投入每增加1%会使得创新产出变化的百分比。具体构造如下:
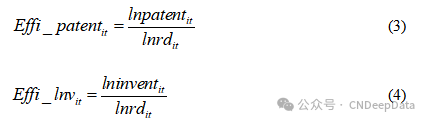
本文在基准回归中使用(3)式计算企业创新效率,即使用发明专利申请量对数lninvent与研发投入对数lnrd的比值作为基准回归指标。稳健性检验使用(4)式计算企业创新效率,即采用总专利申请量对数lnpatent与研发投入对数lnrd的比值作为替代性指标。
(3)注意力内容配置。现有文献表明公司年报可以有效反映企业家的特质及状态(Marquez-Illescas et al.,2019)。参照蒋艳辉和冯楚建(2014)的研究,本文选择对上市公司年报中的管理层分析与讨论章节(Management Discussion and Analysis,MD&A)进行文本分析。
文本分析首先需要构建“创新注意力”词集。参照胡楠等(2021)和Brochet et al.(2015),本文通过机器学习Word2vec这一方法寻找近义词,缓解人为定义词表的主观性和通用同近义词工具的弱相关性(LeCun et al., 2015)。利用Word2vec模型对文本语料进行训练后,生成词向量空间,为每个词分配一个向量。在向量空间中,距离越近的词意思越近,可以通过两词的距离计算相似性。
具体筛选词集方式如下:第一步为选择既往中文文献中曾用过的“创新注意力”词集作为基础词(黄珊珊和邵颖红, 2017),其中包括:“创新”、“自主”、“研发”、“科研”、“新产品”、“技术”、“开发”、“研究”、“专利”。第二步根据Word2vec中的CBOW模型(连续词袋模型,Continuous Bag-of-words Model)对中文年度财务报告语料进行训练,生成词向量空间。并在词向量空间中,对基础词的相似词进行筛选。筛选标准为:财报文本语料中出现频次在1000次以上,且和基础词频相似度在30%以上的拓展词。第三步为邀请了3名业界和学术界专家对CBOW模型得到的相似词进行人工核查,并筛选出包括“发明”和“技术成果”等额外的“创新注意力”拓展词集。
本文将“创新注意力”基础词集和“创新注意力”拓展词集分别作为文本分析的词典,并基于词典法对每家企业的年报中MD&A部分进行词频分析。通过计算词集中词汇总词频占MD&A总词频的比例并乘以100,得到企业家创新注意力配置指标。为了验证稳健性,本文还计算了两个指标:词集总词频占不含数字MD&A总词数的比例,词集总词频占不含数字和英文MD&A总词数的比例。这两个指标数值越大,表示企业家越注重创新。
(4)注意力时间配置。本文采用对企业年报中MD&A一章进行文本分析的方法来测量企业家注意力时间配置。使用文本分析测度人们的时间配置有着较强的语言学理论基础(Chen, 2013)。跟上述做法相似,分三个步骤选取表征当下和表征未来的词集。第一步参照陈守明和胡媛媛(2016)的做法,采用“现在”“此时”“此刻”“当下”“当前”“近期”“目前”作为表征关注当下的基础词,采用“未来”“即将”“将来”“将要”“接下来”“今后”作为表征将来的基础词。第二步基于Word2vec中的CBOW模型构造词向量空间,并在其中寻找近义词,筛选出词频数在1000词以上,和基础词相似度在30%以上。第三步邀请3名业界和学术界专家对CBOW模型得到的相似词进行人工核查,并筛选出包括 “现在”、“此时”等表征当下的词集,并得到包括“将来”、“将要”等表征未来的词集。
本文分别基于表征当下和表征未来的词集用来文本分析,并利用词典法对每家企业的年报中MD&A部分进行词频分析,分别计算以下三个指标:词集词频数占MD&A总词数的比例,词集词频数占不含数字MD&A总词数的比例,词集词频数占不含数字和英文MD&A总词数的比例。
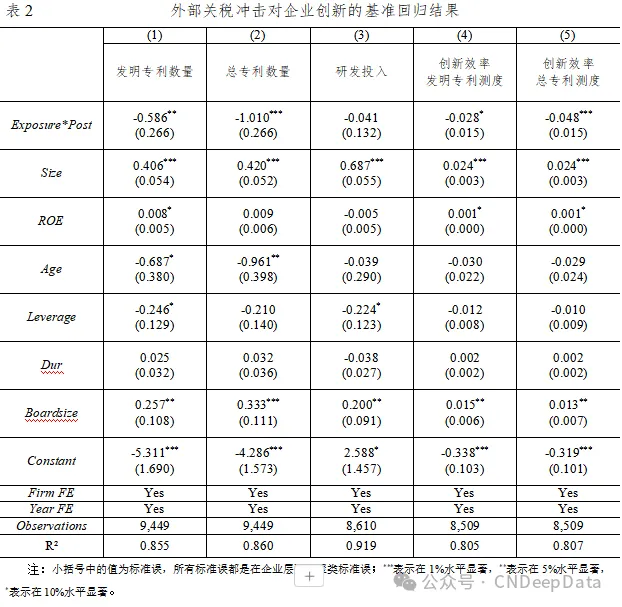
为了检验外部关税冲击对企业创新影响,本文分别将不同创新指标代入(1)式回归。其中表2中第(1)和(2)列分别选择企业的发明专利申请量和企业的总专利申请量作为被解释变量。结果显示,企业受到的关税冲击程度与企业创新产出均呈显著的负相关关系。exposure × post的系数显示,企业受到关税冲击程度每上升 1%,企业发明专利申请下降0.59%;企业总专利申请下降1.01%。表2中第(3)列以企业研发投入作为被解释变量,exposure × post的系数显示,外部关税冲击对企业创新投入的影响并不显著。表2中第(4)列和(5)列分别以企业的创新效率作为被解释变量。无论是以发明专利数量还是总专利数量和创新投入的比值作为测算企业创新效率指标,外部关税冲击均对企业创新效率呈现显著的负向影响。exposure × post的系数显示,企业受到的关税冲击程度每上升1%,基于发明专利数量测算的创新效率下降2.8%,基于总专利数量测算的创新效率下降 4.8%。以上结果说明关税冲击对企业创新呈现出显著负向影响,且这种负向影响主要表现为企业创新效率的下降。
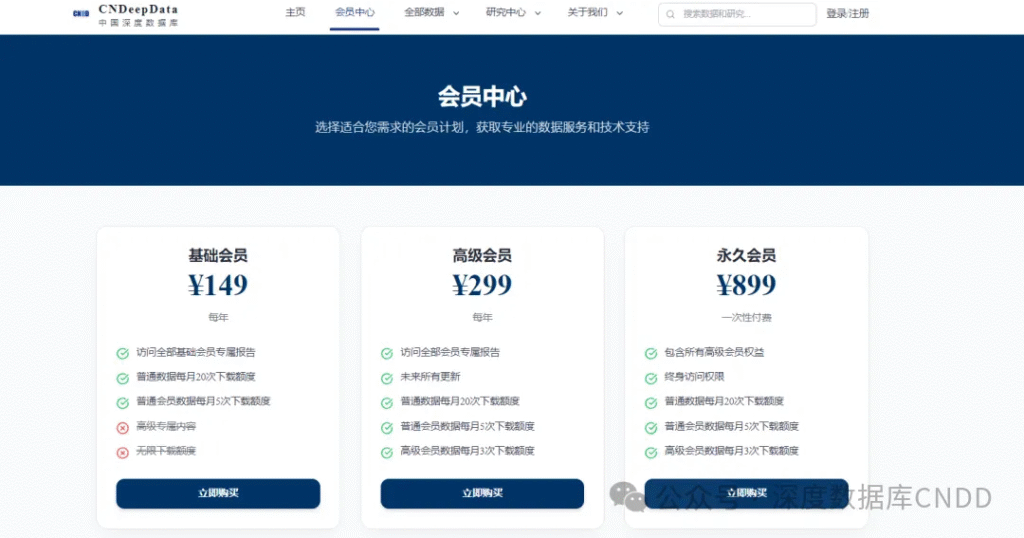
本数据为高级会员专属数据,添加客服微信,购买年度高级会员299元,永久高级会员899元,可享CNDeepData所有数据免费获取。
▪ 客服微信方式:
扫描下方二维码,或搜索下方微信号。

1. 除中国深度数据库(CNDD)特殊声明外,CNDD对基于合法来源的数据的选择、整理和编排具有独创性。任何自然人、法人、其他组织未经CNDD授权,不得以任何目的截取、上传、下载、复制、修改、使用、编译等或者以任何方式任何媒介传播上述作品的任何部分,否则视为侵权。
2. 对于存在侵害CNDD上述权利违法行为的主体,CNDD保留依法追究其法律责任的权利。
任何使用CNDD数据等产品的单位和个人,承诺只将CNDD的数据等用于学术研究,并在所得研究成果(包括但不限于学术论文、咨询报告等)中注明数据来源于CNDD。数据来源的注明方式请参考:“本研究数据来源于中国深度数据库CNDD”;英文参考:“We get the data from CNDeepData (CNDD)”。

中国深度数据库:让精品数据 得以流动
CNDeepData:Let high-quality data flow without barriers
部分图片来源于网络,如涉侵权请告知,本站将第一时间删除。客服微信号:DeepData001