01 数据介绍
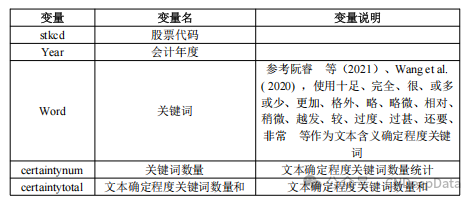
▪ 数据名称: 文本含义确定程度
▪ 数据编号:0267
▪ 数据层级:A股上市公司层面
▪ 数据范围:2007-2023年
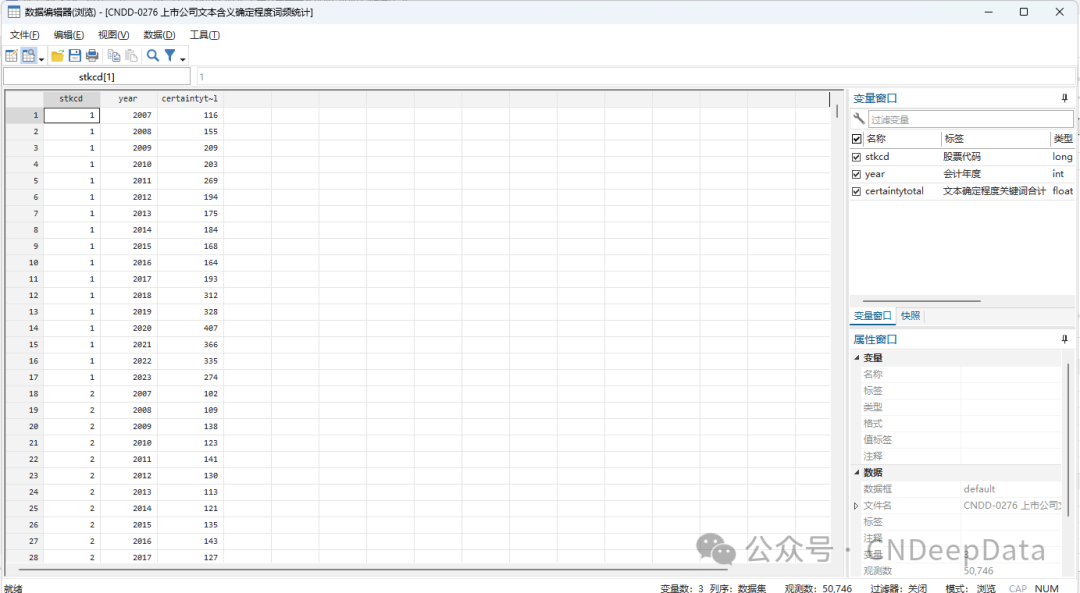
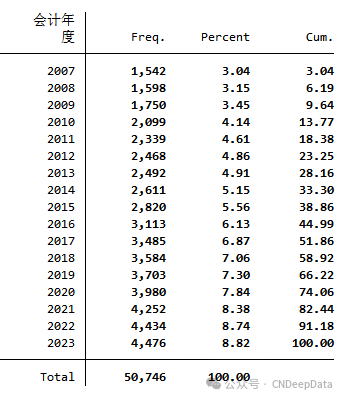
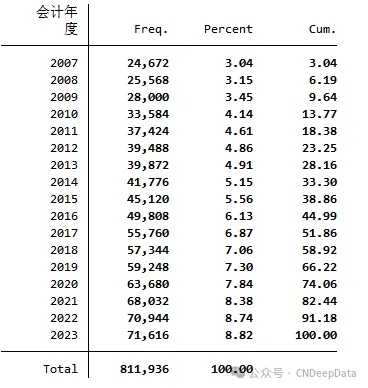
▪ 样本数量:文本含义确定程度关键词明细数据811,936条;文本含义确定程度关键词统计 50,746条
▪ 数据来源:根据上市公司年报文本爬取
▪ 数据说明: CNDD上市公司风险信息文本数据包括风险信息文本关键词明细及风险信息文本统计。参考许文瀚等(2019) ,统计了上市公司年报文本中含有“风险信息文本”相关的词频明细及合计数据。数据提供.xlsx和.dta两种格式,可用stata或excel打开。
▪ 数据维度:年度数据
CNDeepData 数据应用质量评级
▪ 常用度:★★★★☆
▪ 稀缺度:★★★★★
▪ 新颖度:★★★★★
▪ 总体级别:14颗星
✔ 常用度:是数据市场中需求指标,是指该数据在经济管理类学术论文中使用频率。
✔ 稀缺度:是数据市场中供给指标,是指该数据在其他数据库的出现频率。
✔ 新颖度:是数据市场中生成指标,是指该数据在生成时方法新颖程度和工作量。
文本含义确定程度词频统计数据
文本含义确定程度关键词明细数据
▪ 变量分布
文本含义确定程度词频统计数据
文本含义确定程度关键词明细数据
▪ 文献来源:
阮睿,孙宇辰,唐悦,等.资本市场开放能否提高企业信息披露质量?——基于“沪港通”和年报文本挖掘的分析[J].金融研究,2021,(02):188-206.
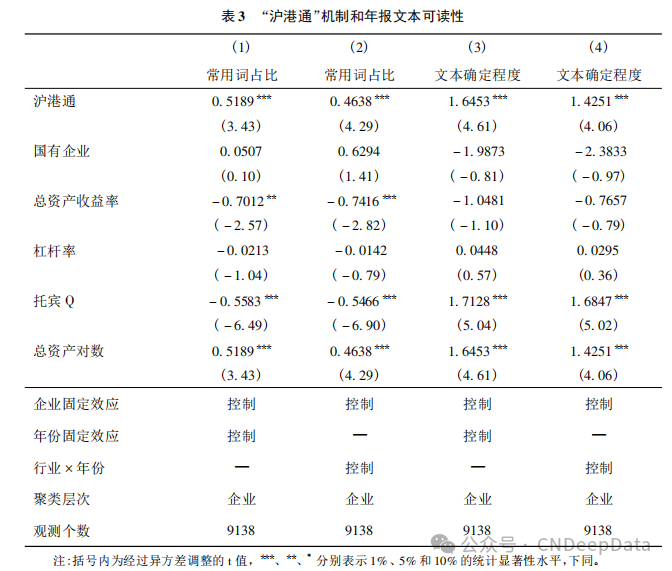
提高信息披露质量对于改善上市公司治理结构和保护股东权益具有重要意义。本文利用 2014 年开通的“沪港通”机制这一准自然实验,研究资本市场开放是否提高了企业的信息披露质量。从 2010 - 2019 年 A 股上市公司年报文本中提炼可读性指标衡量信息披露质量,使用匹配和双重差分方法进行实证研究,发现“沪港通”机制实施以后,标的公司( 纳入“沪港通”的 A 股上市公司) 的信息披露质量显著提高。这一结论对不同的估计方法、样本区间及控制变量组均保持稳健。异质性分析表明,对于盈余操纵水平较高、股价信息含量较低的企业,资本市场开放能够更好地改善其信息披露质量。本文丰富了资本市场开放对企业行为和绩效影响的实证研究,为继续推进资本市场开放政策提供了理论依据。
为验证资本市场开放会促使企业改善年报信息披露的质量,本文构建了如下回归模型:
![]()
其中,Yit 代表公司信息披露质量的特征。本文使用年报文本中常用词占比和文本确定程度衡量公司的信息披露质量。Treatit 表示 i 公司在 t 年是否被纳入“沪港通”机制。控制变量方面,Xit 表示公司层面的其他控制变量,φjt 表示所有行业乘以年份虚拟变量,δi表示企业个体固定效应,本文还使用了在企业层面上聚类的稳健标准误。需要注意的是,本文构建的回归模型是一种双重差分的设计。Treatit 本身代表实验组和处理时间的交互项,而实验组变量和处理时间变量分别和个体固定效应与时间固定效应完全多重共线,其系数无法估计得到,故在回归模型中省略。本文主要关注 Treatit 的回归系数 β1。
1. 被解释变量: 年报文本可读性
本文基于上市公司年报文本构建信息披露质量指标,主要考虑到如下因素。首先,年报文本质量相对较高。上市公司年报编制需要严格遵循中国证券监督管理委员会制定的《公开发行证券的公司信息披露内容与格式准则第 2 号———年度报告的内容与格式》( 以下简称《准则》) 。《准则》明确要求年度报告内容应真实准确,语言通俗易懂,避免空洞和模板化。因此,相对于业绩发布会及电话会议等非正式沟通方式,年报是最为可靠的文本信息来源,对可能存在语言及文化差异的境外投资者尤其如此。其次,与 Yoon( 2020) 不同,本文希望考察公开信息的披露质量,这要求所有市场参与者都能够方便地获取该信息。上市公司年报恰好满足该特征。作为上市公司信息披露制度的核心,年报需发布在中国证监会指定的国际互联网网站上,境内外投资者都可以方便地查阅。综上可知,考虑到年报文本的规范性和可得性,本文选定年报文本来构建信息披露质量指标。年报文本最初为 PDF 格式文件,为了把这些文件清洗成便于分析的格式,本文首先将其转为 TXT 格式的文本文件,并且去掉了所有转换后为乱码的文件,然后使用 Python编程语言进行文本预处理。本文使用正则表达式剔除掉所有数字、英文字符和空字符( 即空格、缩进符、换行符等) 。保留的标点符号有句号( 。) 、中文问号( ?) 、中文感叹号( ! ) 、中文分号( ; ) 、中文逗号( ,) 、中文冒号( : ) ,其他标点符号均予剔除。接下来,本文提取并计算了如下文本可读性指标:
(1) 常用词占比。使用 Python 的第三方库 Jieba 对年报文本进行分词处理。为了减少专业词汇导致分词出现歧义的情况,笔者加载了金融类自定义词典。金融类自定义词典中包括所有 A 股上市公司的全称和股票简称、会计和金融专业术语等。然后,笔者整理《现代汉语常用词表》收录的汉语常用词,作为统计出现在年报文本里的常用词集。考虑到金融专业词汇对于投资者通常是常用词语,但可能并没有收录于不针对特定领域的《现代汉语常用词表》中,笔者进一步把分词使用的金融类自定义词典与汉语常用词表合并,作为最终的常用词集。对于每一篇年报文本,笔者把分词得到的词语列表长度记为总词数; 然后统计常用词在文本中出现的总次数,记为常用词数量; 常用词占比为常用词数量/总词数 × 100。
2) 文本确定程度。参考 Wang et al. ( 2020) 使用的词库?,本文使用其中“程度级别词语”用来构建文本含义确定程度指标。这个文件列举了 6 类中文程度级别词语,详细内容见表 1。笔者认为级别 1、2、6 在程度上表示确定的含义,说明公司管理层通过年报文本向股东传递了确定的信息; 而级别 3、4、5 在程度上表示不确定的含义,传递的信息是模糊的。笔者统计了每一类词语在年报文本中出现的次数,把级别 3、4、5 词语出现的次数求和,记为程度模糊词语数量; 把级别 1、2、6 词语出现的次数求和,记为程度确定词语数量; 把 6 类词语出现的次数求和,记为总程度级别词语数量。文本的确定程度为: ( 程度确定词语数量 - 程度模糊词语数量) /总程度级别词语数量 × 100。

2. 解释变量: “沪港通”变量
本文的核心解释变量是公司是否被纳入“沪港通”机制。公司被纳入“沪港通”机制的当年及之后年份,该公司的“沪港通”变量取值为 1。如果该公司被剔除出“沪港通”机制,则在下一年该变量的取值变为 0。其余的公司 - 年份观测均取值为 0。
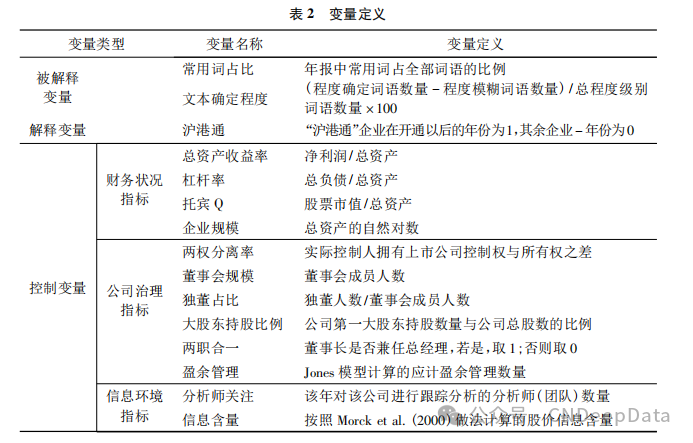
本文回归分析使用的所有变量的定义见表 2。
[1]王成龙,吴忧.年报风险信息披露模仿行为研究:基于LDA主题模型分析[J/OL].世界经济,2024,(11):183-205[2024-12-04].
[2]陈怡欣,张俊瑞,马晨.客户年报风险信息披露的溢出效应——基于供应商企业创新的研究[J/OL].财经论丛,1-11[2024-12-04].
[3]张淑惠,周美琼,吴雪勤.年报文本风险信息披露与股价同步性[J].现代财经(天津财经大学学报),2021,41(02):62-78.
见推文末尾。
本数据为高级会员专属数据,添加客服微信,购买年度高级会员299元,永久高级会员899元,可享CNDeepData所有数据免费获取。
添加客服微信,购买年度高级会员299元,永久高级会员899元,可享CNDeepData所有数据免费获取。
▪ 客服微信方式:
扫描下方二维码,或搜索下方微信号。

1. 除中国深度数据库(CNDD)特殊声明外,CNDD对基于合法来源的数据的选择、整理和编排具有独创性。任何自然人、法人、其他组织未经CNDD授权,不得以任何目的截取、上传、下载、复制、修改、使用、编译等或者以任何方式任何媒介传播上述作品的任何部分,否则视为侵权。
2. 对于存在侵害CNDD上述权利违法行为的主体,CNDD保留依法追究其法律责任的权利。
任何使用CNDD数据等产品的单位和个人,承诺只将CNDD的数据等用于学术研究,并在所得研究成果(包括但不限于学术论文、咨询报告等)中注明数据来源于CNDD。数据来源的注明方式请参考:“本研究数据来源于中国深度数据库CNDD”;英文参考:“We get the data from CNDeepData (CNDD)”。

中国深度数据库:让精品数据 得以流动
CNDeepData:Let high-quality data flow without barriers
部分图片来源于网络,如涉侵权请告知,本站将第一时间删除。客服微信号:DeepData001